SQL Server has allowed storage of binary data in the database at least since SQL Server 2000. With the release of SQL Server 2005, the IMAGE data type was subsequently planned for deprecation and replaced by VARBINARY(max). The IMAGE data type still works and is still supported in SQL Server 2019, however the VARBINARY(max) data type is the recommended replacement for IMAGE.
With each new version SQL Server included additional data types to store and/or access binary data, including FILESTREAM and subsequently FileTable - more information about these can be found in the SQL Server documentation.
This white paper describing the FILESTREAM feature of SQL Server 2008 written by Paul S. Randal (SQLskills.com) provides a detailed explanation of the FILESTREAM data type.
Corruption
So you’ve got your database maintenance jobs all set up and running, possibly using the Ola Hallengren SQL Server Maintenance Solution, all jobs have an appropriate schedule, logging and notifications are in place, and everything is running smoothly, until…
…the Database Integrity Checks job fails with this error message:
Cannot find the FILESTREAM file "00000123-00012345-0001" for for column ID 4 (column directory ID 3532c474-1a4f-4ac8-8b0f-6b8ee5e6fa6a container ID 65537) in object ID 3277624322, index ID 0, partition ID 72056345252711562, page ID (1:223556). slot ID 22.
CHECKDB found 0 allocation errors and 1 consistency errors in table 'dbo.MyDocuments' (object ID 3277624322).
CHECKDB found 0 allocation errors and 1 consistency errors in database 'AdventureWorks'.
repair_allow_data_loss is the minimal repair level for errors found by DBCC CHECKDB (AdventureWorks).
The above error provides the following important pieces of information:
- Database name: AdventureWorks
- Table name: dbo.MyDocuments
- Object ID: 3277624322 (redundant since we already have the schema and object name in the error message)
- Page ID: (1:223556)
- The name of the missing File: 00000123-00012345-0001
- Slot ID: 22
The folder naming for a table configured to store FILESTREAM data is explained by Paul Randal himself in the FILESTREAM directory structure blog post.
Checking the FILESTREAM folder for the file “00000123-00012345-0001” showed that this was in fact missing. The only way a file can be missing is if it was deleted or moved out of the FILESTREAM folder by someone with permissions to that folder. The folder is restricted, so this could only have been done by someone having Administrator privileges.
Further investigation (and linking a separate incident reported by ITSEC) revealed that the file was actually moved to Quarantine because the Antivirus software detected malicious content in the binary data. Quite possibly, some of the binary data matched a signature for known malware, triggering the Antivirus software to Quarantine the file. Since the AV services would be running under the context of the SYSTEM account, this would have sufficient privileges to access the FILESTREAM folder and move the FILESTREAM file.
Replicate the error
In order to demonstrate the error we’ll be expanding on the code samples from the FILESTREAM directory structure blog post.
First we’d have to ensure that the FILESTREAM option is enabled for the Instance. This can be found in the SQL Server Configuration Manager, within the SQL Server service Properties, under the FILESTREAM tab.
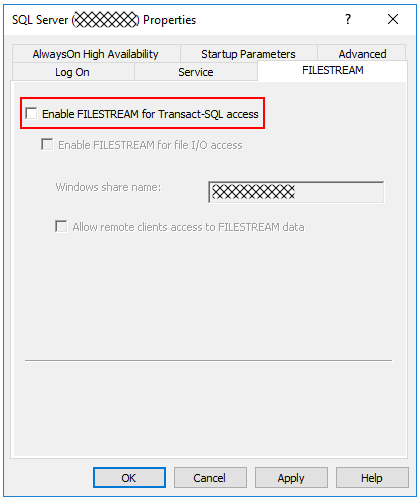
For this example we are going to “Enable FILESTREAM for Transact-SQL access” only.
Once done we also have to enable the “filestream access level” configuration option.
USE [master]
GO
EXEC sys.sp_configure 'filestream access level', 1;
RECONFIGURE WITH OVERRIDE;
GO
Now we’ll create a sample database:
USE [master]
GO
CREATE DATABASE [FileStreamTestDB];
GO
We are also going to create the folder parent structure to store the FILESTREAM files:
USE [master]
GO
EXEC sys.xp_create_subdir N'D:\MSSQL\DATA\FileStreamTestDB';
GO
Next we’re going to add a FILEGROUP which supports FILESTREAM:
USE [master]
GO
ALTER DATABASE [FileStreamTestDB] ADD FILEGROUP [FileStreamGroup1] CONTAINS FILESTREAM;
GO
Now we’ll add a “file” to the FILEGROUP:
USE [master]
GO
ALTER DATABASE [FileStreamTestDB] ADD FILE (
NAME = [FSGroup1File], FILENAME = N'D:\MSSQL\DATA\FileStreamTestDB\Documents')
TO FILEGROUP [FileStreamGroup1];
GO
We can now create the table which will store the binary data:
USE [FileStreamTestDB]
GO
CREATE TABLE [MyDocuments] (
[DocId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,
[DocName] VARCHAR (25),
[Document] VARBINARY(MAX) FILESTREAM);
GO
Let’s generate some sample data:
USE [FileStreamTestDB]
GO
SET NOCOUNT ON;
INSERT INTO [MyDocuments] VALUES (NEWID (), 'Document1.doc', CAST (REPLICATE('D1', 500) AS VARBINARY(MAX)));
INSERT INTO [MyDocuments] VALUES (NEWID (), 'Document2.doc', CAST (REPLICATE('D2', 500) AS VARBINARY(MAX)));
INSERT INTO [MyDocuments] VALUES (NEWID (), 'Document3.doc', CAST (REPLICATE('D3', 500) AS VARBINARY(MAX)));
INSERT INTO [MyDocuments] VALUES (NEWID (), 'Spreadsheet1.xls', CAST (REPLICATE('S1', 500) AS VARBINARY(MAX)));
INSERT INTO [MyDocuments] VALUES (NEWID (), 'Spreadsheet1.xls', CAST (REPLICATE('S2', 500) AS VARBINARY(MAX)));
GO
We can check that the data is actually there:
USE [FileStreamTestDB]
GO
SET NOCOUNT ON;
SELECT * FROM [MyDocuments];
GO

And we can also see the files:
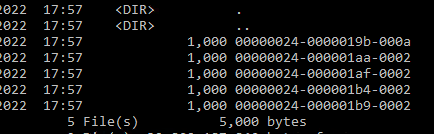
Running DBCC CHECKDB, as a baseline, shows that the database is in fact intact:
USE [master]
GO
DBCC CHECKDB([FileStreamTestDB]) WITH NO_INFOMSGS, ALL_ERRORMSGS;
GO
Now, if we go back to our Command Prompt, delete one of the files, then run the DBCC command again we get this error message:

We have just replicated what the Antivirus did when it moved the file/s to Quarantine.
Fix
Recovering the file from Quarantine wasn’t an option as it was flagged as containing malicious content. We would have to identify the file in the database and delete it. This would have been a more challenging task to do since the mapping between the binary data, the record, and the actual file name used by SQL Server did not exist. The only information we had was that shown in the error message above.
DBCC TRACEON (3604);
DBCC PAGE ([FileStreamTestDB], 1, 336, 3);)
Bear in mind that the DBCC PAGE command would return a sizeable amount of information - it is an 8 KB dump of the entire Page after all.
The output will be similar to this:
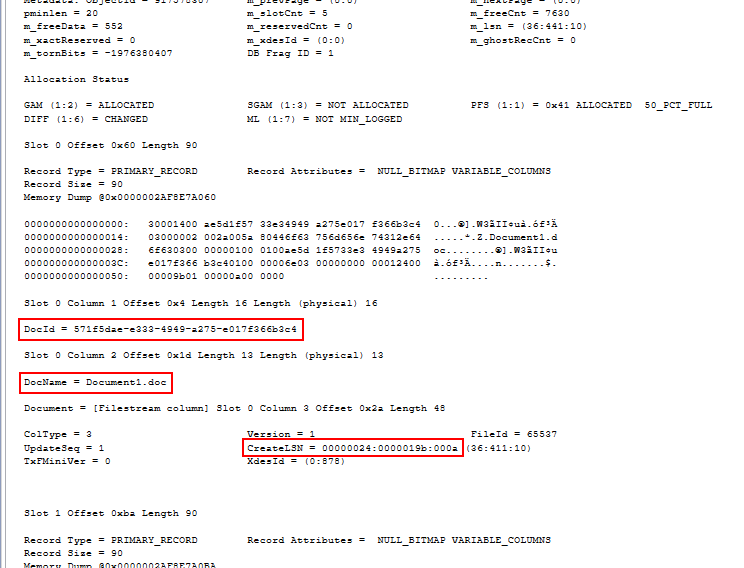
Scrolling through the output to “Slot 0” we can clearly see the GUID used for the record identifier, the original file name, as well as the LSN (Log Sequence Number) of the transaction which was used to generate the FILESTREAM file name “00000024-00000019b-000a”.
Using this information we can identify the record in the table, and hence any records referencing this file. The end user was then asked to delete the file using the application interface, then upload a clean (virus-free) copy.
One comment in the FILESTREAM directory structure blog post suggested creating an empty file (e.g. using a text editor), then renaming the file to “00000024-00000019b-000a” to “trick” the database into completing the DBCC CHECKDB command. This did in fact work and can be used to mitigate the reported “database corruption”, especially since your ITSEC team would (understandably) be reluctant to release file containing malicious content back into production.
Conclusion
What is surprising is that the Antivirus moving or deleting a file from a FILESTREAM folder can actually get the database flagged as corrupt, which is an actual headache for DBAs.
Unfortunately there is no way that a DBA can know what type of files are being uploaded to the database. An application could potentially allow executables, script files, or other file types, and these could get flagged by the Antivirus leading to the scenario mentioned. Once again it is the responsibility of the Developers and the End Users to ensure that the files being uploaded have been scanned and do not contain malicious content.
Since the [Microsoft] FILESTREAM white paper mentioned above could be removed at some point, you may also download it from here.